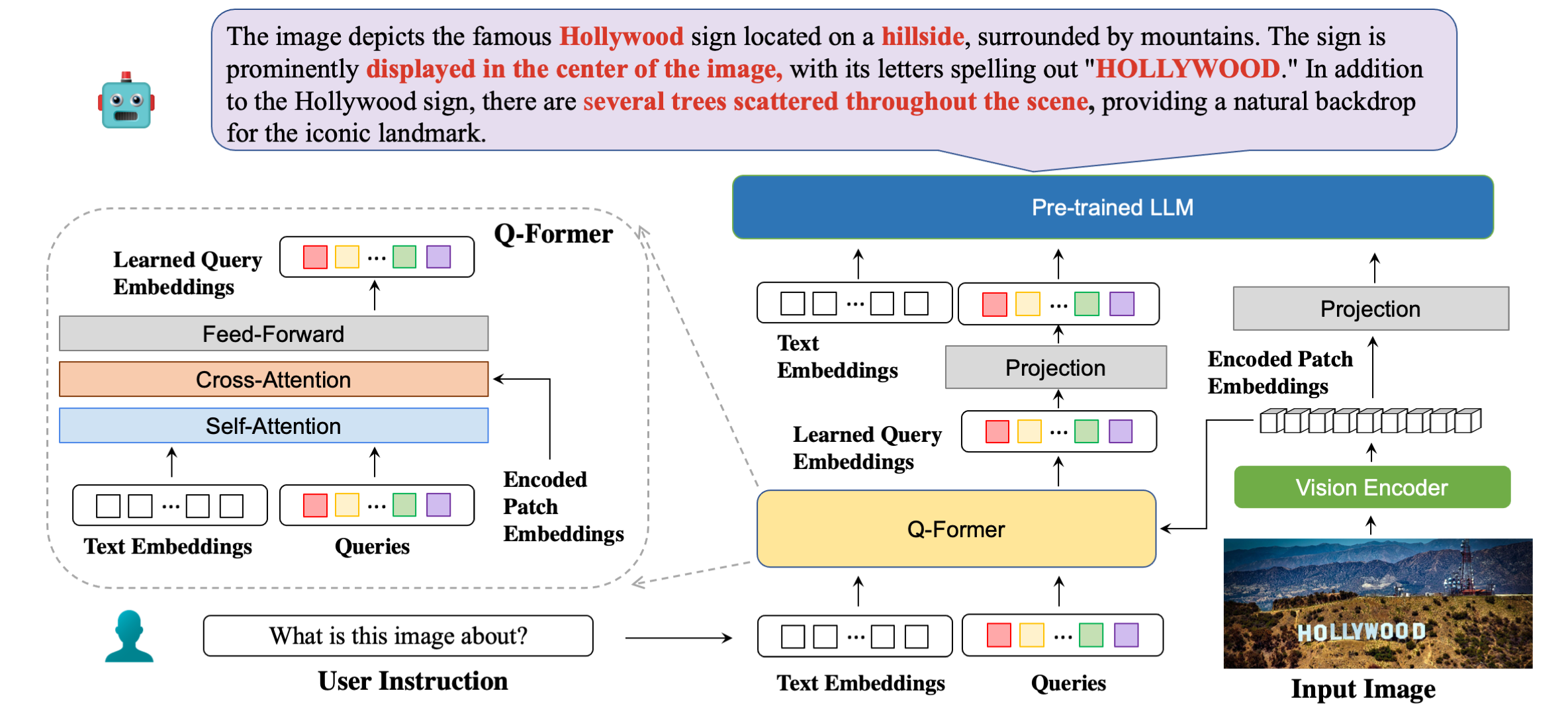
Vision Language Models (VLMs), which extend Large Language Models (LLM) by incorporating visual understanding capability, have demonstrated significant advancements in addressing open-ended visual question-answering (VQA) tasks. However, these models cannot accurately interpret images infused with text, a common occurrence in real-world scenarios. Standard procedures for extracting information from images often involve learning a fixed set of query embeddings. These embeddings are designed to encapsulate image contexts and are later used as soft prompt inputs in LLMs. Yet, this process is limited to the token count, potentially curtailing the recognition of scenes with text-rich context, particularly those require Optical Character Recognition (OCR).
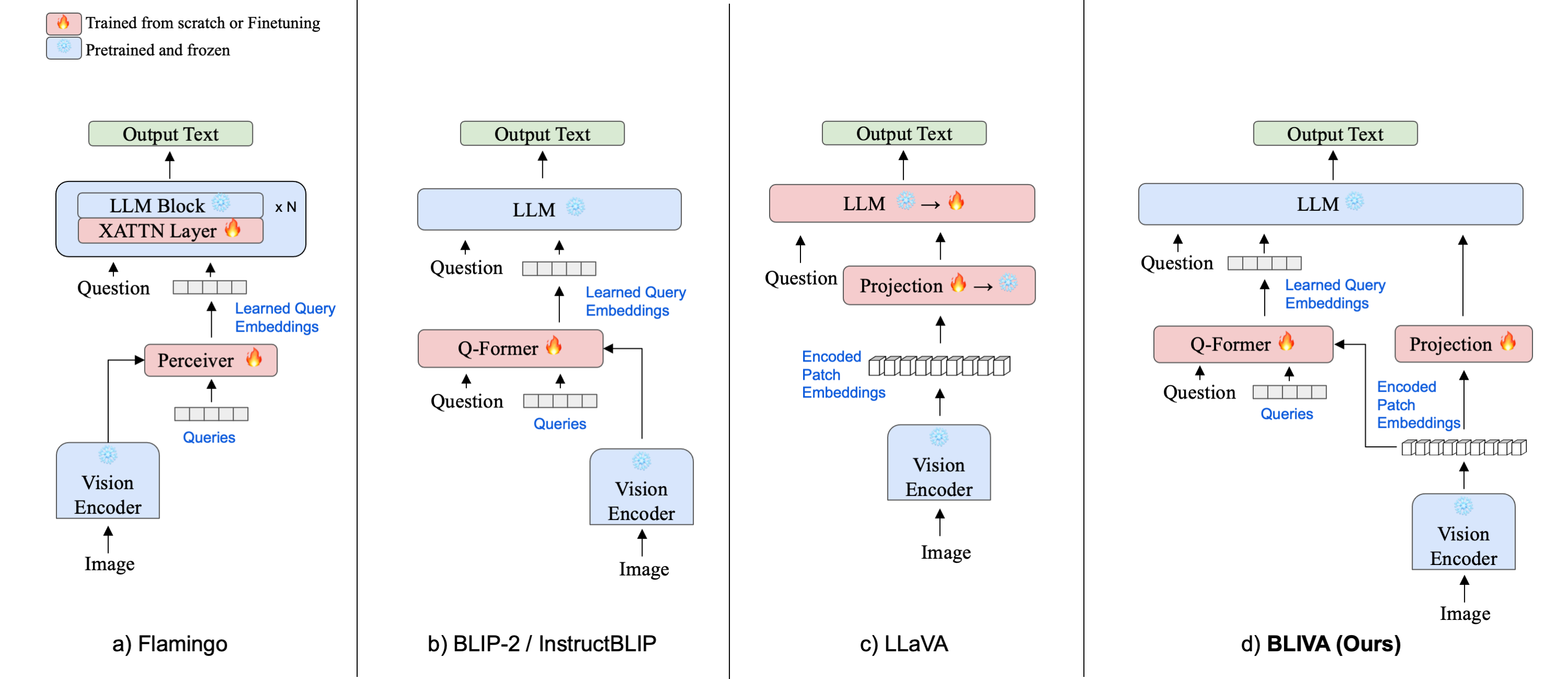
To improve upon them, we introduces an augmented version of InstructBLIP with Visual Assistent (BLIVA) an end-to-end large multimodal model retains the query embeddings from InstructBLIP, while also directly projecting encoded patch embeddings into the LLM inspired by LLaVA, thereby enriching the model with any intricate details that might be lost during the query decoding process.
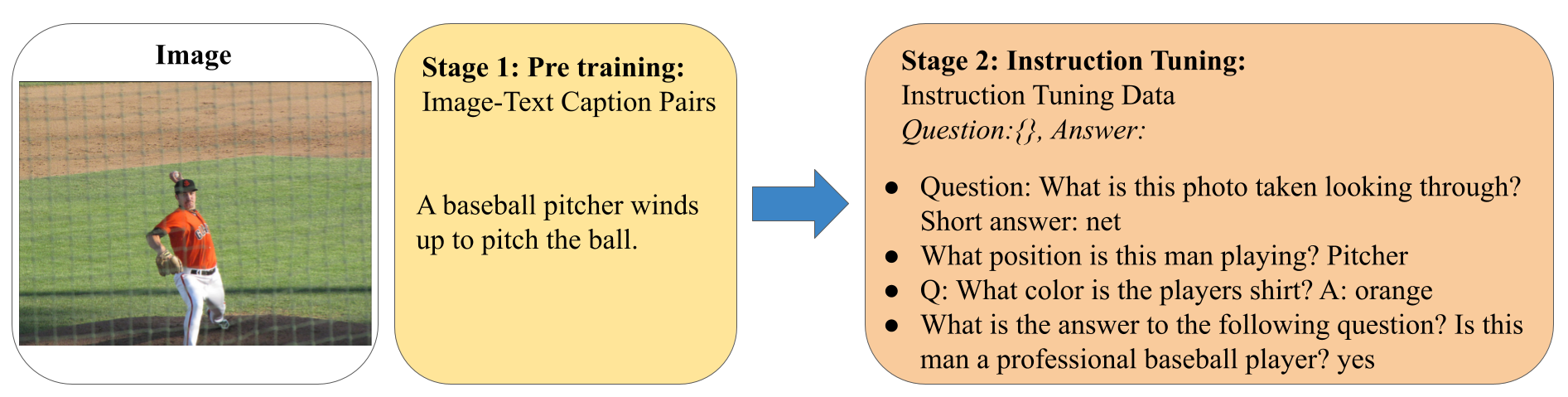
We initialized our model from InstructBLIP and employed same training data to demonstrate the effectiveness of our design. A typical training paradigm, two-stage training is further utilized to first introduce a global description alignment between vision feature and LLM and then employ instruction tuning for detailed understanding viusal feature as languages.
Empirical evidence demonstrates that our model, BLIVA, notably improves the performance in processing text-rich VQA tasks (up to 17.76% in OCR-VQA benchmark) and in undertaking typical VQA tasks requires spatial reasoning (up to 7.9% in Visual Spatial Reasoning benchmark), comparing to our baseline InstructBLIP. BLIVA exhibits considerable potential in decoding real-world images, regardless of the presence of text.
To underscore the wide-ranging industry applications made feasible by BLIVA, we assess the model under a new dataset encompasses YouTube thumbnails with questions-answer pairs across a diverse spectrum of 13 categories.
A typical multi-stage training paradigm. We follow the paradigm established by InstructBLIP. The training process involves two key stages. For Q-former, the first stage is done by BLIP-2 where image and text caption pairs are pre-trained to accomplish a raw alignment between visual and language modalities. As for patch feature, we followed LLaVA to use the same pre-training dataset. In the second stage, the alignment is further refined using instruction tuning VQA data, which facilitates a more detailed understanding of visual inputs based on language instructions.
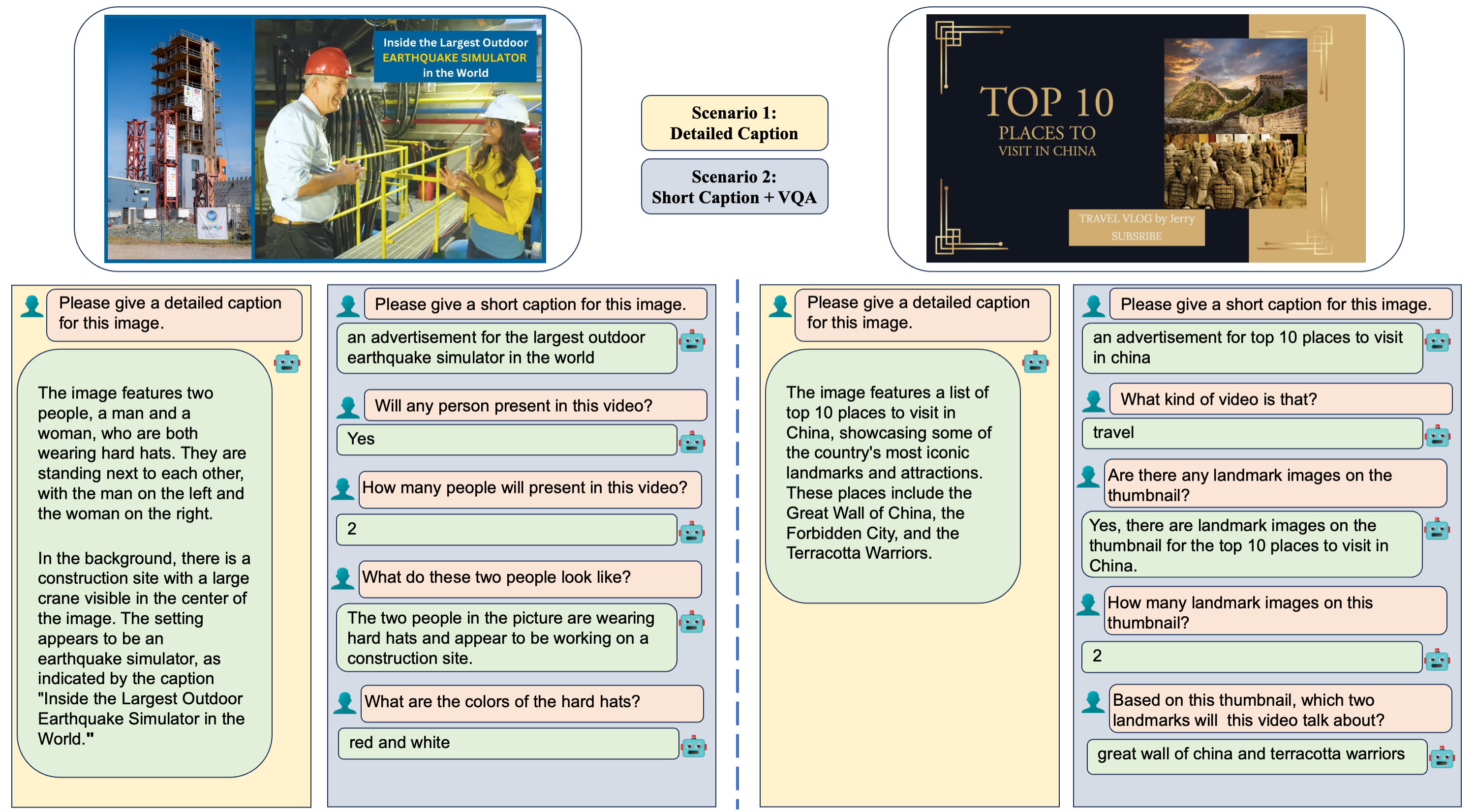
Two examples from our collected Youtube Thumbnails Visual Questioan Answer Dataset, YTTB-VQA. We have two scenarios for BLIVA's applicable use: (1) Detailed Captions. BLIVA can give a detailed caption describing all the visual information in the image. (2) Short Captions + VQA. BLIVA can also summarize the visual information to a short caption,followed by its ability to field more detailed visual queries posed by users.
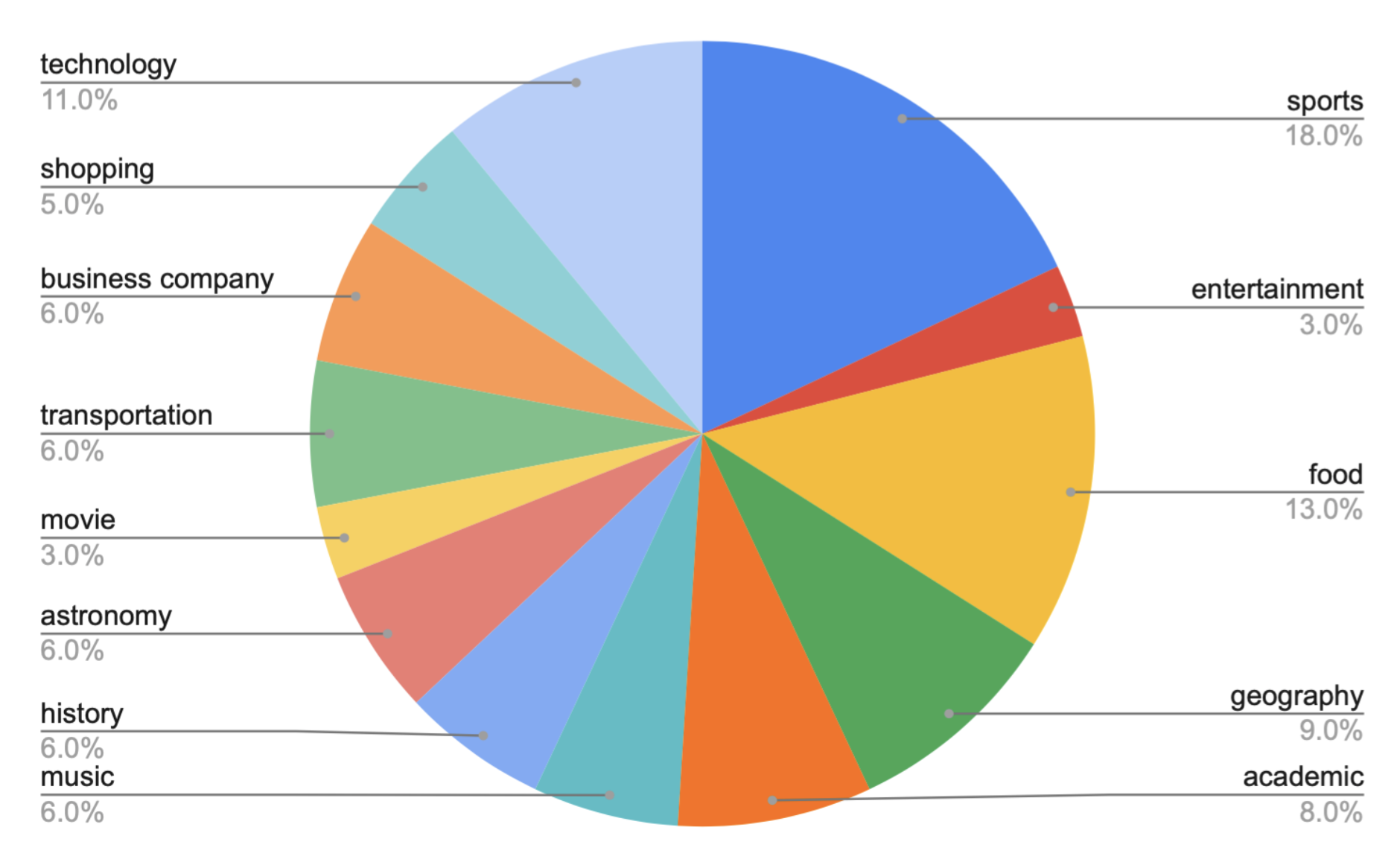
Our collected Youtube thumbnails datasets from Youtube official website. This Chart illustrates the distribution of 13 categories including technology, shopping, sports, entertainment, business companies, transporation, food, moive, astronomy, history, music, geography and academic sharing.
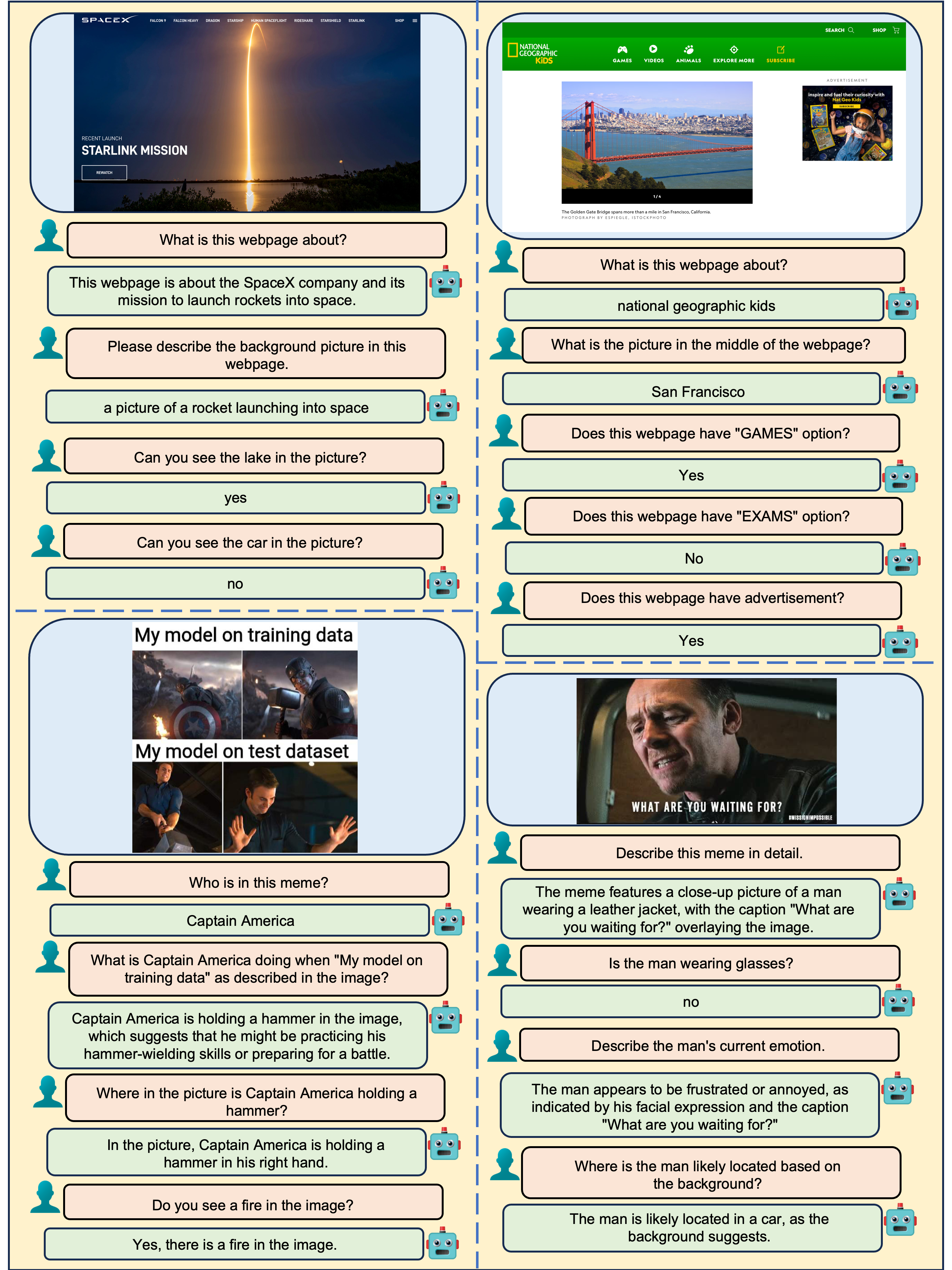
We employ real life scene images, movie poster, webpages and memes to demonstrate our model's performance regarding interaction with humans based on text-rich images. BLIVA demonstrates great OCR abilities in reading the road signs, food packaging, movie posters, webpages and texts in the memes. BLIVA understands the visual information and can localize the texts and objects in the imags clearly. BLIVA's reply is strictly based on visual content without hallucination like InstructBLIP. Beyond reading the texts, BLIVA demonstrates its understanding in the meaning of the memes by combining both the text and visual information together.

@article{Hu_Xu_Li_Li_Chen_Tu_2024,
title={BLIVA: A Simple Multimodal LLM for Better Handling of Text-Rich Visual Questions},
volume={38},
url={https://ojs.aaai.org/index.php/AAAI/article/view/27999}, DOI={10.1609/aaai.v38i3.27999},
author={Hu, Wenbo and Xu, Yifan and Li, Yi and Li, Weiyue and Chen, Zeyuan and Tu, Zhuowen},
year={2024},
month={Mar.},
pages={2256-2264}
}